

Table of Contents
What is search engine spider ?
Search engine spider sometimes called web crawler is a program or algorithmic software which is used to discover websites and web pages by following links. It crawls from one webpage link to another in search of content. It indexes and stores the set of web page links in search engine databases. There are different types of crawlers or spiders at search engines like Google, Bing, etc. A website can be crawled by different types of crawlers like Googlebot news, Googlebot image, Googlebot video, etc. the crawlers of Google, for using different types of products and services in the sites.
How does Search engine spider work?
Spiders or web crawlers are operated by thousands of machines of search engines. They are designed to be run on the web to discover and scan web pages. They can recognize hyperlinks of the web pages and crawl one webpage to another by following links. Thus web crawlers discover new and updated web pages and move to crawl one page to another through links around the web. Here web crawling is the process of recognizing, copying, and storing the content of the web pages for indexing purposes.
A website owner can also ask spiders or web crawlers to crawl or index web pages by submitting URLs in the search engine. Either way, when the crawlers find a webpage, search engine systems render only the content of the page. If the crawlers find new and updated data in the web content, they index them which are unique and relevant, and store in the database in the queue for ranking. The index is like an ever-growing library as it contains hundreds of billions of web pages in the database of the search engine server. Here the indexing process is like the index in the back of a book where an entry is made for every significant word seen on every webpage in the title, heading, meta tags, alt tags, subtitles, and other important positions. Thus web crawlers gather information from a large number of web pages and organize it in the Search index.
Crawling and indexing are cyclical issues. But it is not certain that crawling must lead to indexing. However, crawling will take time for a page to be indexed. Indexing can take up to a week or 2 or more. In some cases, crawling pages may not be indexed at all due to some issues. Consequently, the pages won’t appear in search engine results. After solving the issues, it is possible to request crawlers for crawling and indexing the pages again.
Also, it is possible to block web crawlers from crawling and indexing a page on a site or a complete site. There are a number of options to block web crawlers to keep private your data.
Why is Website Crawling and indexing Important?
Crawling and indexing are prerequisite steps to showing up data in the Search Engine Result Pages (SERPs). Again ranking in the SERP is another important step to show your content in the first page or first position of the result page. If ranking is not done successfully, the content will never be visited by the users. If you want to get your content in the first of the search query results, your content needs to be crawled, indexed, and ranked well.
What is the role of a spider in ranking a webpage?
When the spider visits a web page, the results are put onto Google’s index which is later led to rank on the SERPs. Ranking is the placement process of the resulting content page in the search engine result pages (SERP) depending on relevancy to the search queries and the quality of backlinks pointing to the page.
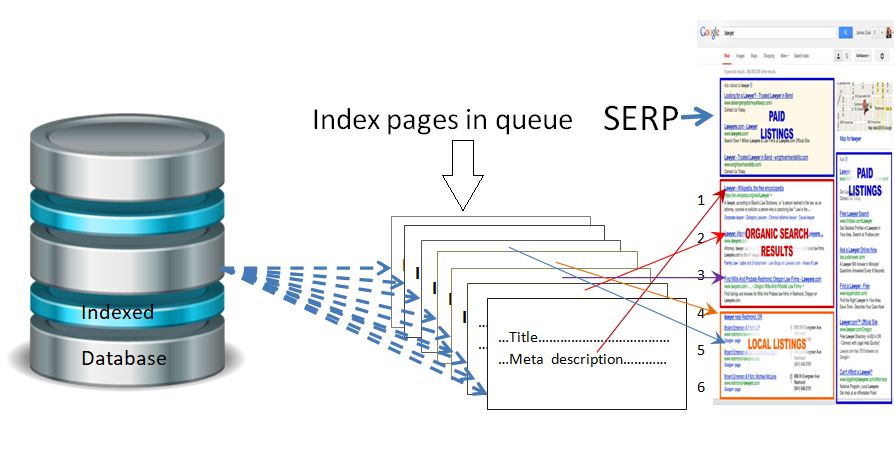
The search engine considers different factors before deciding which web pages are more important to rank. It also emphasizes backlinks which means how many other authority pages are linked to those pages. Thus the indexed pages of the spiders are ranked and shown on the search engine result page.
Conclusion
This is briefly a simple description of Search Engine Spider and how does it work. There might be a lot of secrets hidden behind. No search engine generally wants to reveal its secrets. Now I would like to hear about your experience.
Related term: